多模态大模型(Multimodal Large Models)作为人工智能领域的新兴概念,引起了广泛的关注。这种模型不仅仅是单一数据模态的处理者,而是能够同时处理多种类型的数据,例如图像、文本、音频等,从而使得机器在理解和交互方面更加灵活和智能。本文将探讨多模态大模型的概念、优势以及推荐几种目前备受关注的多模态模型。
多模态大模型是指在一个统一的框架下,集成了多种不同类型数据处理能力的大型神经网络模型。这些模型能够处理图像、文本、音频等不同的数据模态,并在这些模态之间进行有效的交互和信息整合。与传统的单模态模型相比,多模态大模型更加灵活和全面,能够更好地模拟人类对于不同感知模态信息的整合和理解能力。

1、全面性
多模态大模型能够同时处理多种数据模态,使得机器在理解世界的过程中更加全面和深入。例如,在理解一个视频内容时,模型可以同时考虑视频中的图像、音频以及文本信息,从而更准确地把握视频的语义和情感。
2、信息整合
多模态大模型能够有效地整合不同模态之间的信息,提高模型对于复杂现实世界的理解能力。这种信息整合能力使得模型能够更好地理解数据之间的关联性和语义关系,从而提高了模型的表现力和泛化能力。
3、语境感知
多模态大模型能够更好地理解语境和背景信息,使得模型在处理复杂任务时更加准确和智能。例如,在进行图像描述生成时,模型可以同时考虑图像内容和描述语境,生成更加准确和连贯的描述结果。
4、跨模态迁移
多模态大模型能够实现不同模态之间的知识迁移和共享,从而提高模型的效率和泛化能力。这种跨模态迁移使得模型在不同任务和领域之间能够更好地进行迁移学习和知识共享,从而加速了模型的训练和优化过程。
1、CLIP(Contrastive Language-Image Pre-training)
CLIP是由OpenAI提出的一种多模态大模型,通过对图像和文本数据进行联合训练,实现了对图像和文本之间语义关系的学习。CLIP模型在多种视觉和语言任务上取得了state-of-the-art的表现,展示了多模态大模型在理解和交互方面的潜力。

2、ViLBERT(Vision-and-Language BERT)
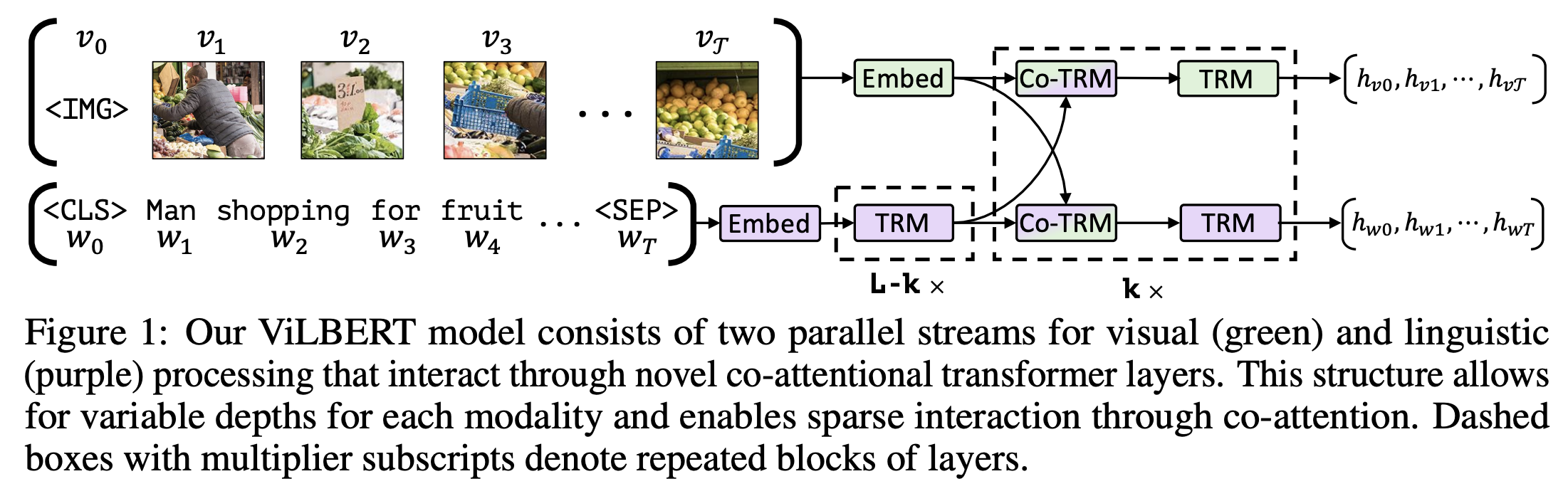
ViLBERT是一种由微软研究院提出的多模态大模型,通过联合预训练图像和文本数据,实现了对视觉和语言之间语义关系的学习。ViLBERT模型在视觉问答、图像描述生成等任务上取得了优异的性能,证明了多模态大模型在自然语言处理和计算机视觉领域的有效性。
3、M3
M3是一种由Facebook提出的多模态大模型,通过对图像、音频和文本数据进行联合预训练,实现了对多模态数据的全面理解和交互。M3模型在多模态推理、跨模态迁移等任务上取得了令人瞩目的成果,为多模态大模型在实际应用中的推广奠定了基础。
4、万兴“天幕”大模型
万兴“天幕”是一个以音视频生成式AI技术为基础的多媒体创作垂类大模型,由视频大模型、音频大模型、图片大模型、语言大模型组成,聚焦数字创意垂类创作场景。万兴“天幕”众多能力已在万兴科技旗下创意软件产品,尤其是海外产品中规模化商用。万兴科技面向视频营销领域,推出AI数字人营销视频创作神器“万兴播爆”,具备丰富的专业级场景化模板和超逼真多国籍AI数字人功能,可一键生成AIGC“真人”出海营销短视频,已广泛应用于跨境电商视频营销等场景。

多模态大模型作为人工智能领域的新兴概念,具有广阔的应用前景和研究价值。随着对多模态数据理解和处理能力的不断提升,相信多模态大模型将会在未来的人工智能发展中发挥越来越重要的作用,推动人工智能技术的进一步发展和应用。