生成对抗网络(GAN)是一种强大的深度学习模型,其通过竞争性训练生成器和判别器来生成逼真的数据。而条件生成对抗网络(CGAN)在这一框架下添加了条件信息,使得生成的数据可以根据给定的条件进行精确控制。在本文中,我们将深入探讨CGAN的原理、结构以及其在各个领域的应用。
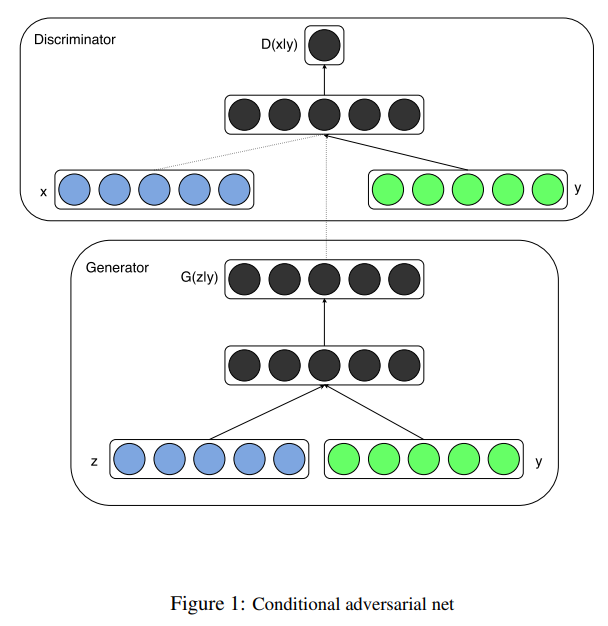
CGAN是由生成器和判别器组成的,其基本原理与传统的GAN相似。生成器试图生成逼真的数据样本,而判别器则尝试区分生成的样本与真实数据。与传统的GAN不同之处在于,CGAN在生成过程中接收了额外的条件信息。这些条件信息可以是任何形式的辅助输入,例如类标签、图像、文本等。生成器和判别器通过这些条件信息进行交互,以生成符合条件的逼真样本。
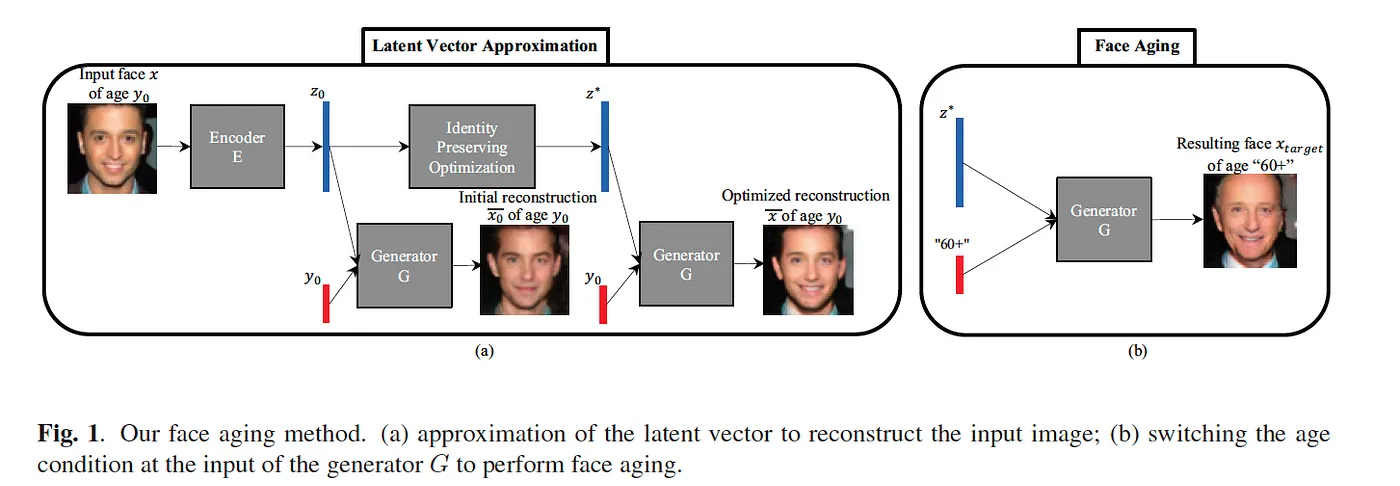
1、生成器(Generator)
生成器的输入由两部分组成:随机噪声向量(通常服从某种特定的分布,如均匀分布或正态分布)和条件信息。这两部分被联合输入到生成器的网络中,以产生与条件信息相匹配的逼真样本。生成器的结构通常是一个由多个隐藏层组成的神经网络,其中包含了反卷积层或转置卷积层,以逐步将输入转换为与真实数据相似的输出。
2、判别器(Discriminator)
判别器的输入也包含了条件信息,其任务是评估生成的样本与真实数据之间的差异。与生成器类似,判别器通常也是一个神经网络,其输出一个概率值,表示输入样本是真实数据的概率。在训练过程中,判别器被训练以尽可能地将生成的样本与真实样本区分开来。
CGAN的训练过程与传统的GAN类似,但需要额外的条件信息。在每个训练迭代中,生成器和判别器都会被更新。生成器试图生成逼真的样本以欺骗判别器,而判别器则试图识别出生成的样本与真实样本之间的差异。训练过程持续进行直到达到设定的停止条件,通常是生成器和判别器的损失收敛到某个稳定状态或训练达到一定的轮数。
1、图像生成
CGAN在图像生成领域具有广泛的应用,例如生成高清晰度图像、图像修复、图像风格转换等。通过在生成器和判别器中引入条件信息,可以实现对生成图像的精细控制,例如指定生成的人脸具有特定的表情、姿势或发型。

2、文本到图像的生成
CGAN还可以用于文本到图像的生成任务,例如根据文本描述生成与之相符的图像。在这种情况下,文本描述将作为条件信息输入到生成器中,生成器根据这些描述生成对应的图像。
Tips:数字人生成
万兴播爆是一款引领潮流的AI视频制作工具,其独特的智能脚本功能和支持文案直接操控AI数字人创作视频的特性,让其在视频制作领域占据了重要地位。

条件生成对抗网络(CGAN)通过在生成过程中引入条件信息,使得生成的样本具有更高的可控性和逼真度。其在图像生成、图像转换和文本到图像生成等任务中展现出了广泛的应用前景。随着深度学习技术的不断发展,CGAN在各个领域都将发挥越来越重要的作用,为人们提供更加丰富多样的数据生成和转换方法。