近年来,随着人工智能技术的不断发展,声音克隆技术成为了一个备受关注的领域。RVC声音克隆技术作为其中的一种,具有很高的效果和广泛的应用场景。本文将介绍RVC声音克隆技术的基本原理、优势以及使用方法。
RVC是Retrieval based Voice Conversion的缩写,是一个基于VITS的开源工具,可实现实时声音变换,适用于直播、视频录制等场景。

RVC声音克隆技术(Retrieval-based-Voice-Conversion-WebUI)是一种基于深度学习的声音合成技术。其核心原理在于通过深度学习模型训练,将输入的语音样本与目标说话者的语音特征进行学习和匹配。随后,利用这个模型对新的文本进行语音合成,使得合成的语音听起来就像目标说话者一样。该技术是一款开源工具,集模型训练、推理和音频处理为一体,全称为Retrieval-based-Voice-Conversion-WebUI,是基于VITS的简单易用的语音转换框架。它能够接受音频输入,并以经过模型训练的声音输出。此前,主要应用于游戏变声。RVC具有实现克隆说话人声音的功能,包括歌曲翻唱和实时变声,且具备低延迟和优秀的变声效果。
RVC最新版本V2 0528可在Huggingface上下载。RVC需要高配置的电脑,建议采用13代酷睿处理器、64GB内存和4070ti以上显卡。该工具仅支持Nvidia显卡。首先,下载RVC安装包和模型包,并解压。然后运行程序,选择声音模型并导入Pth文件。连接麦克风和声卡,或使用虚拟声卡。配置设置后,点击开始进行实时变声。用户还可以自行训练模型。

高保真度: RVC声音克隆技术能够实现高度逼真的语音合成,合成的语音质量非常高,几乎可以媲美真实的人类语音。
实时性: RVC声音克隆技术可以实时合成语音,响应速度非常快,适用于需要即时生成语音的场景。
可定制性: 用户可以根据自己的需求定制不同的语音合成模型,实现不同风格、不同语气的语音合成。
但是,它的缺点就是只支持音频,不支持直接文字转音频,所以只能是先通过某些 TTS 工具将文字转成音频后再进行推理,相对来说,比较麻烦。
步骤一:准备语音样本
首先,需要准备目标说话者的语音样本,样本数量越多越好,以提高合成语音的准确度和逼真度。
步骤二:训练模型
利用准备好的语音样本,训练RVC声音克隆模型。在训练过程中,模型将学习目标说话者的语音特征,以便后续的语音合成。
步骤三:语音合成
训练完成后,就可以利用训练好的模型进行语音合成了。输入待合成的文本,模型将生成与目标说话者相似的语音。

RVC声音克隆技术具有广泛的应用场景,其中包括但不限于以下几个方面:
1、语音助手
通过为语音助手赋予不同的说话风格和声音特点,使其更具个性化和人性化,提升用户体验。
2、语音合成
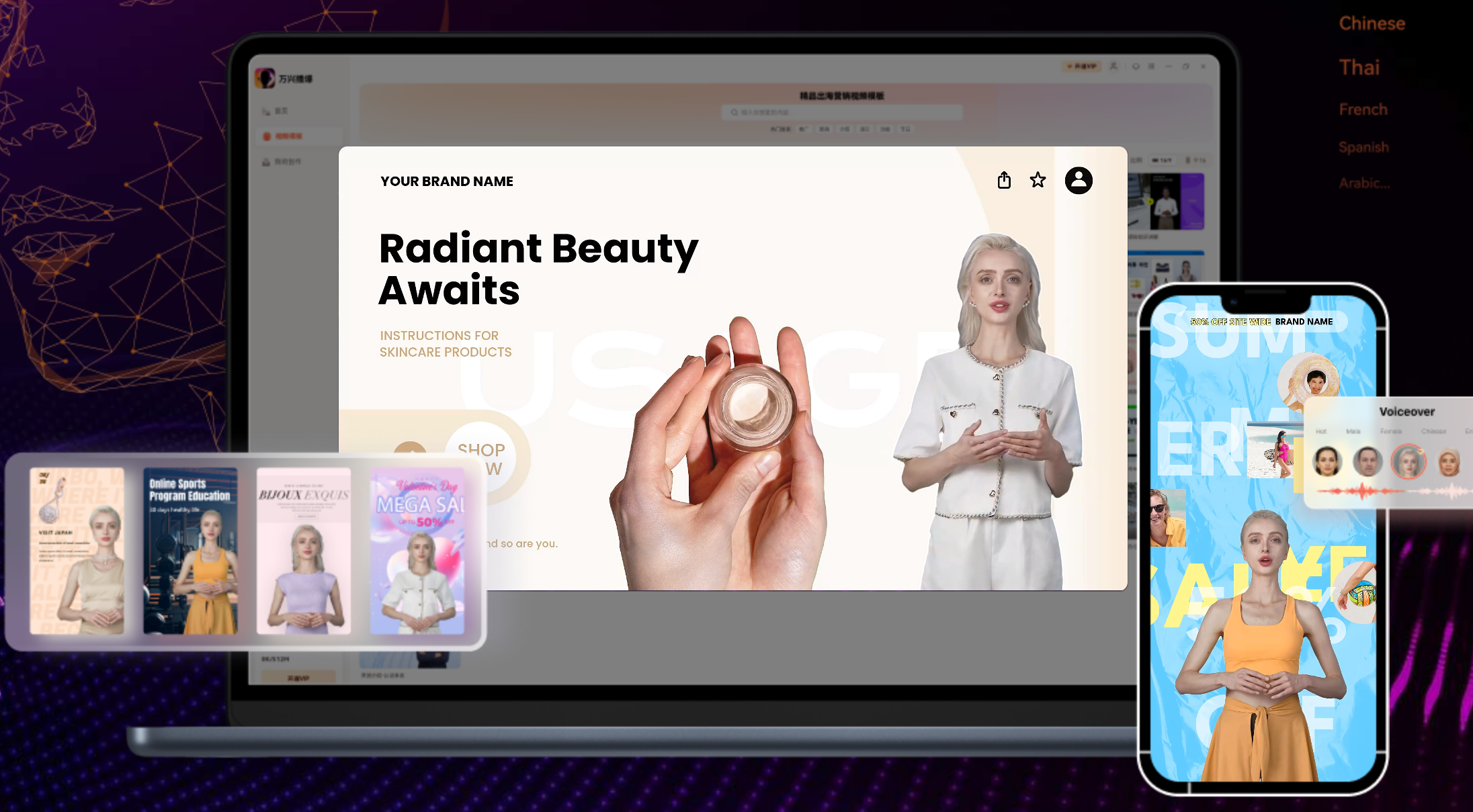
在需要实时语音合成的场景中,如广播、电台、视频配音等,RVC声音克隆技术可以被应用,以生成自然、流畅的语音内容。例如国内的万兴播爆,利用其天幕大模型,支持声音克隆与形象克隆,轻松定制个性化数字人视频。关于声音克隆软件详见:声音克隆软件推荐。
3、个性化语音服务
利用该技术为个人定制专属的语音服务,例如个性化语音助手、语音导航等,满足用户对个性化服务的需求,提高服务的质量和用户满意度。
RVC声音克隆技术作为一种先进的声音合成技术,具有高度的实用性和广泛的应用前景。通过深度学习技术,它可以实现高保真度、实时性和可定制性的语音合成,为各种语音相关应用提供了全新的解决方案。