西安交通大学开源的人工智能模型SadTalker(Stylized Audio-Driven Talking-head)引起了广泛关注。这一创新工具在数字人制作领域展示了前所未有的可能性。SadTalker以其独特的功能,让静态照片栩栩如生地动起来,配合音频的节奏进行真实的头部运动和面部表情。它的出现不仅为数字人的创作提供了高效便捷的方式,还推动了数字化媒体的发展。
文章目录
SadTalker的核心技术是基于声音驱动的人脸动画生成。研究人员通过从音频中学习生成三维运动系数,结合全新的三维面部渲染器,实现了音频驱动的头部运动和面部表情生成。这项技术对音频和不同类型运动系数之间的联系进行了显式建模,从而实现了高度精确的面部表情合成。

SadTalker在数字人、虚拟主播等领域有着广泛的应用前景。它可以让静态照片焕发生机,让人物栩栩如生地表达出音频所传达的情感和语气。这一技术突破了传统数字人制作的局限,为人工智能与媒体艺术的融合提供了全新的可能性。
使用SadTalker非常简便。首先,准备清晰高质量的照片和匹配的音频素材。然后,将素材导入SadTalker,进行必要的预处理和调整。接着,SadTalker根据音频文件自动生成数字人的头部运动和面部表情。最后,可以将生成的数字人导出为视频或图片,或进一步进行后期处理和发布。
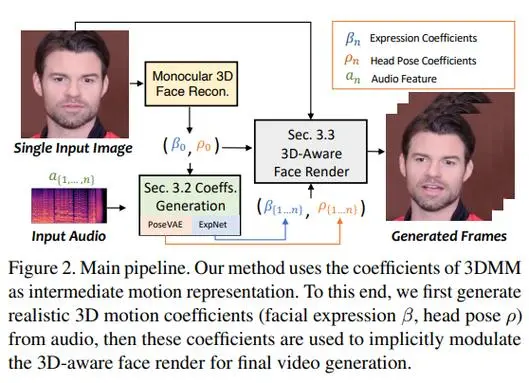
相比其他数字人制作工具,SadTalker具有几个显著的优势。首先,SadTalker不像D-ID和HeyGen等平台,它类似Stable Diffusion,让用户无需支付高昂费用即可享受到先进的数字人制作技术。其次,SadTalker采用了先进的AI技术,生成的数字人表现力强大、逼真度高,可以满足多种应用场景的需求。此外,SadTalker的操作简便,用户无需专业的技术背景,即可轻松上手制作出令人惊叹的数字人。

万兴播爆是国内一款数字人生成工具,支持文本与语音驱动数字人。万兴播爆提供了60多个国籍的数字人,覆盖了120多个国家和地区的语种,包括英语、德语、法语、西班牙语等。这些数字人的形象逼真,能够给观众带来更加身临其境的体验。

随着人工智能技术的不断发展,SadTalker的应用前景将更加广阔。它不仅可以用于数字人创作和虚拟主播,还可以应用于教育、娱乐、广告等领域,为内容创作和传播带来全新的可能性。未来,我们可以期待SadTalker与其他领域的技术相结合,开拓出更多创新的应用场景,推动数字化媒体的发展和普及。
SadTalker作为西安交通大学研究团队的重要成果,为数字人制作注入了新的活力和创意。它不仅代表了人工智能技术的最新进展,更为数字媒体的发展带来了新的可能性。未来,随着技术的不断演进和应用场景的拓展,SadTalker必将在数字内容创作领域发挥越来越重要的作用,成为数字时代创意表达的重要工具之一。