在当今数字化的世界中,人工智能技术的发展正在以前所未有的速度改变着我们的生活方式和商业模式。其中,OpenAI 公司最新推出的 CLIP 大模型(Contrastive Language–Image Pre-training)引起了广泛关注,因其能够将图像和文本的语义关联进行无缝融合,从而开创了一种全新的模式,进一步推动了图像识别与自然语言处理领域的交叉发展。
CLIP 大模型是由 OpenAI 的研究人员于 2021 年发布的一种《多模态大模型https://virbo.wondershare.cn/tech/410013.html》,其核心思想是将文本和图像的信息相互联系起来。这一模型的关键创新在于,它能够通过学习大规模的文本和图像数据集来理解图像和文本之间的关系,而无需额外的标注信息。通过对图像和文本进行共同的编码,CLIP 能够使得模型对图像和文本的理解能力变得更加普适和有效。
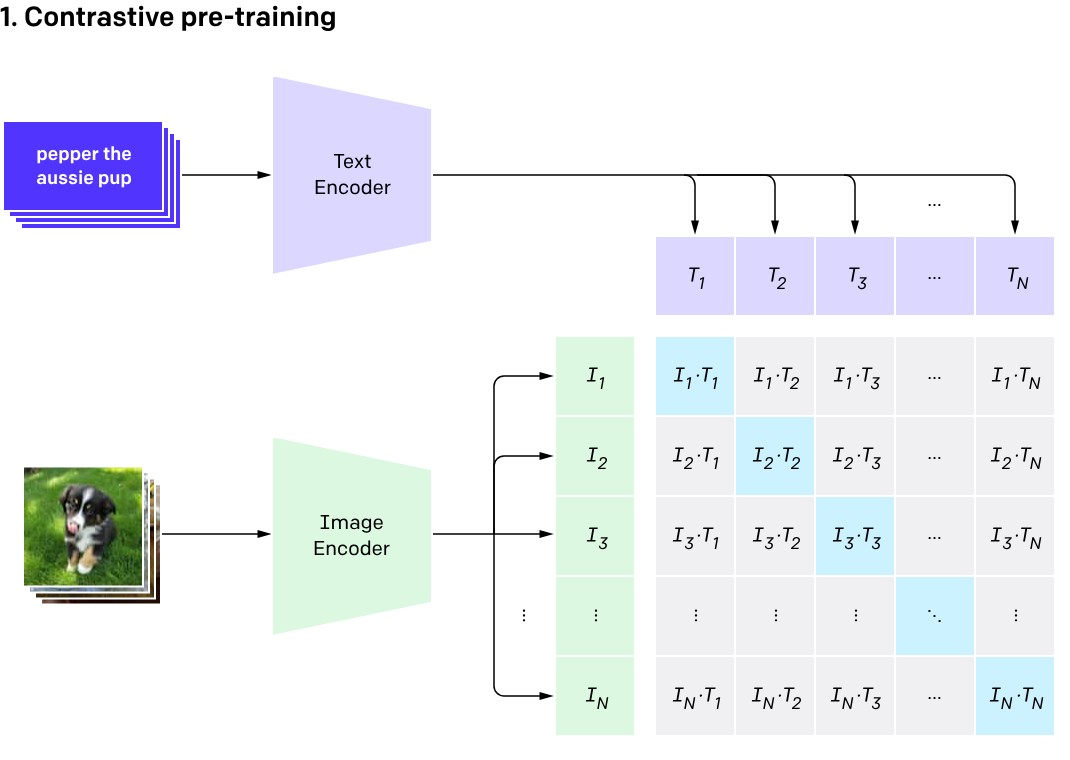
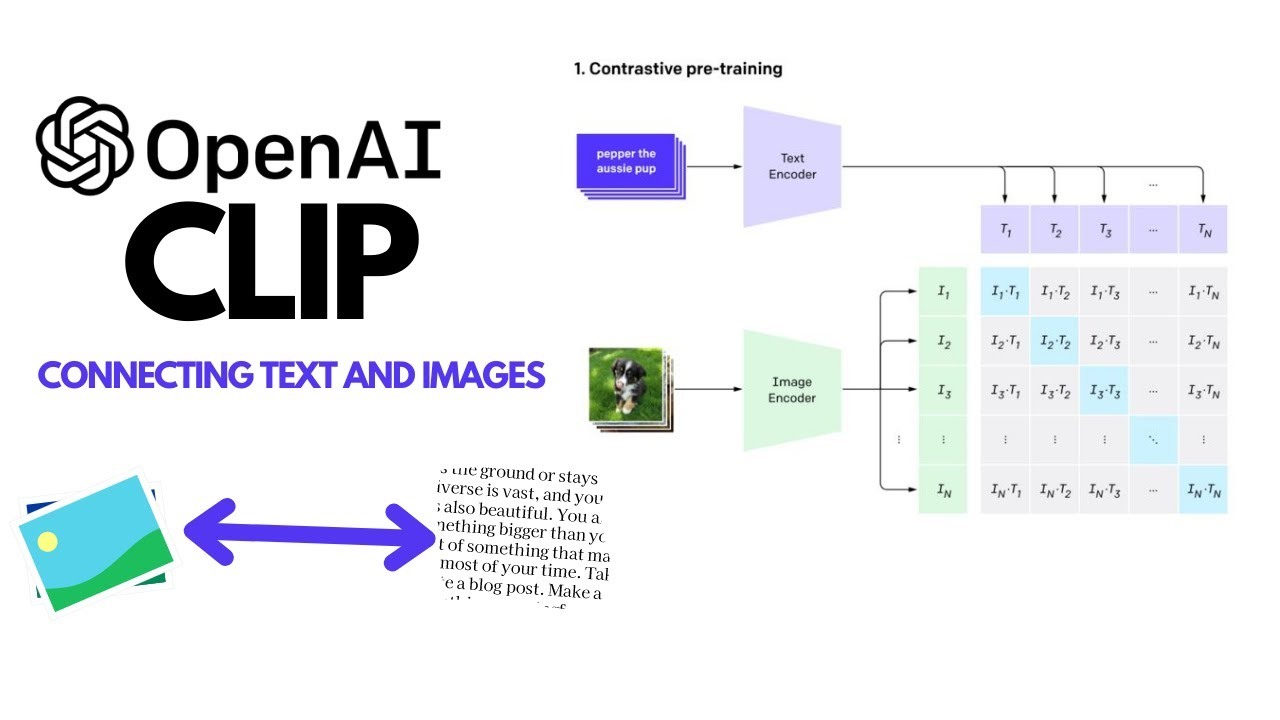
CLIP 大模型的工作原理是基于对比学习(contrastive learning)的思想,通过最大化正确图像-文本对的相似性,最小化错误的图像-文本对的相似性来进行训练。该模型同时学习了一个图像编码器和一个文本编码器,这两者共同形成了一个多模态的表示空间。在推理阶段,CLIP 将图像和文本映射到这个共同的表示空间中,然后通过衡量它们的相似度来进行分类或检索。
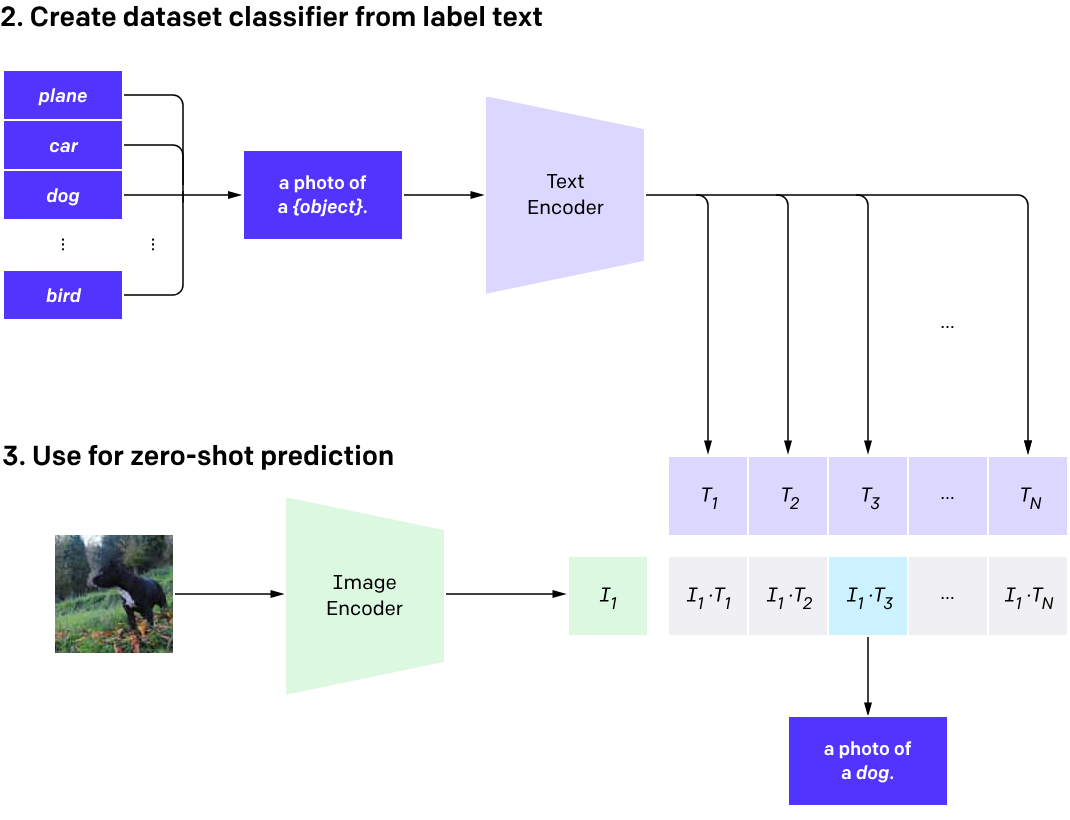
1、图像识别与分类
CLIP 可以通过关联图像和文本来提高图像分类的准确性。例如,通过对图像和文本进行共同编码,模型可以理解到“猫”的图像和文本表示之间的联系,从而实现更精准的图像分类。
2、文本理解与生成
CLIP 使得文本对图像的理解更加准确和自然。通过将文本编码器与图像编码器联合训练,模型可以从文本描述中生成与之匹配的图像。
3、多模态搜索与推荐
CLIP 可以应用于多模态搜索引擎和推荐系统,通过将用户的文本查询与图像数据进行匹配,从而提供更加个性化和精准的搜索结果和推荐。
尽管 CLIP 大模型在多模态学习方面取得了重大突破,但它仍然面临一些挑战和局限性:
1、数据偏差
CLIP 的性能可能会受到训练数据中的偏差和不平衡的影响,导致模型在某些情况下表现不佳。
2、泛化能力
CLIP 在处理一些复杂或抽象的图像-文本关系时可能表现不如人类,其泛化能力仍需要进一步提升。
3、计算资源需求
CLIP 大模型由于其复杂的结构和大规模的训练数据,需要大量的计算资源和存储空间,限制了其在一般设备上的应用范围。
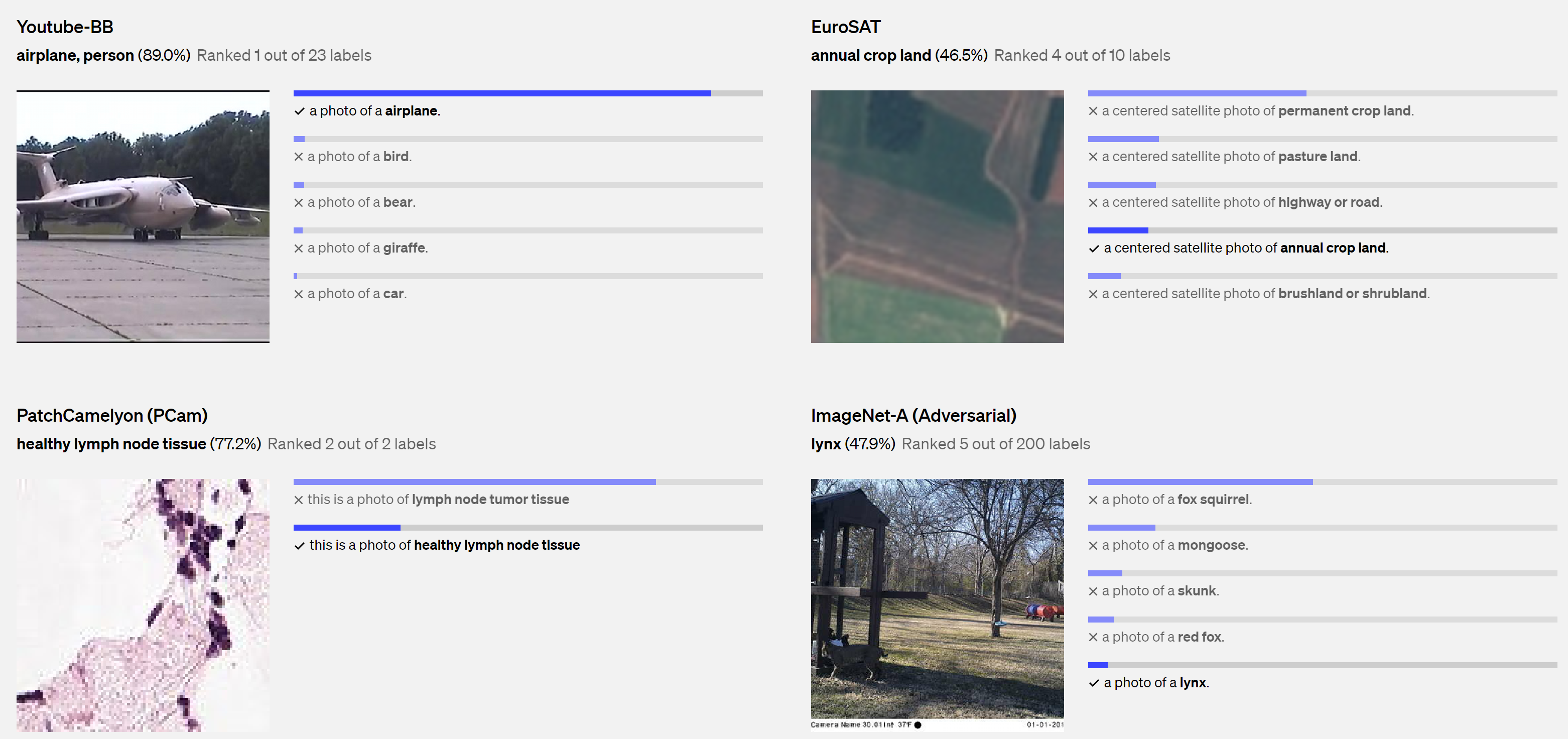
随着人工智能技术的不断发展和应用,CLIP 大模型代表了一种融合图像和文本的新兴趋势,预示着图像识别和自然语言处理领域的进一步融合。未来,随着模型的不断优化和算法的进步,CLIP 可能会在更多领域展现出更广泛的应用前景,为我们带来更加智能和全面的人工智能解决方案。
万兴“天幕”以音视频生成式AI技术为基础,由视频大模型、音频大模型、图片大模型、语言大模型组成,涵盖文生视频、文生3D视频、视频AI配乐、数字人播报等近百项能力,相关能力已在Wondershare Filmora、万兴播爆产品上规模化商用。

总的来说,CLIP 大模型作为一种革命性的多模态学习技术,为图像和文本的融合提供了一种全新的思路和方法。它的问世不仅推动了人工智能领域的进步,也为我们展示了多模态学习在实际应用中的巨大潜力。